Chapter 11 - Sorting (2)

定义
注意
补充、解释
其他
1 Quick Sort
快速排序的核心是分而治之,步骤如下:
- 选主元(Pivot):从数组中任选一个元素作为基准值
- 划分(Partition):将数组拆分为两部分 —— 左边所有元素≤主元,右边所有元素≥主元
- 递归排序:分别递归排序左右两个子数组
- 合并:左右子数组有序后,自然与主元拼接成完整有序数组
1 | void Quicksort(ElementType A[], int N) { |
划分操作
1 | // 挖坑法划分:返回pivot的最终位置 |
最好的情况,每次枢轴基本处于数组中间的位置,每次划分左右数组的元素个数基本相同,这样递归层数就是
每一层进行划分操作,划分遍历数组所有元素即可,复杂度为
时间复杂度是
空间复杂度是
最坏情况,例如数组已经有序,每次pivot选最左边的元素
就要递归N层(递归树是斜的),每层划分
平均情况是
所以选取pivot是关键的,我们给出一种选法
1 |
|
1.1 应用:找第k大的元素
给定一个数组,请找出第k个大的元素
例如[1,3,9,4,6,5,2], k=2答案是6
我们利用快速排序中非常重要的一个性质:选一个主元(枢轴,或pivot),划分左右数组后,主元就已经位于正确的位置
例如我们直接选择6做pivot,先放到最左[6,3,9,4,1,5,2]划分一下得到[2,3,5,4,1,6,9]
6已经位于了最后的位置,所以我们可以直接确定它就是第2大的元素
1 | int QuickSelect(int A[], int Left, int Right, int k) { |
注意每次我们只用处理半边的数组,所以在划分比较均匀的情况下,每次工作量减半
即
或者
而快速排序虽然每层工作量减半,但比如第二层要划分两次,所以总共还是要处理N(-1)个元素
所以每层都是
1.2 另一种划分方法
2 Sorting Large Structures
2.1 Table Sort
我们设想这么一个场景:现在硬盘里有6部电影,我们想按名字顺序播放这些电影
一种方法是,按顺序播放,那么电影的顺序要对,所以我们对6部电影排序
比如用快速排序,那么交换时,我们要把一部电影拷贝到一个tmp中,这个过程开销很大
我们把它转化成排整数就好了
| list | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 首字母 | d | b | f | c | a | e |
| table | 0 | 1 | 2 | 3 | 4 | 5 |
位置0的电影首字母是d,我们不要对list直接排序,对table排序,根据是首字母,得到
| list | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 首字母 | d | b | f | c | a | e |
| table | 4 | 1 | 3 | 0 | 5 | 2 |
table[0]=4意味着排在第一的应该是list[4]
所以我们按list[table[0]], list[table[1]], ...的顺序播放电影即可
2.2 Physically Rerange Structures
如果我们还是想把电影做实际排序呢
Every permutation is made up of disjoint cycles.
permutation指一个0到n-1这n个数的任意一个排列,例如上例的4,1,3,0,5,2
这个环怎么得到呢?给出一种方法,table[0]=4,所以我们从4开始,接着看table[4],得到5,接下来2,接下来3,接下来回到0
另一个环就是1到1到1…
由此启发,更一般地,对于n个数的一种排列,我们把这n个数从左到右从0开始排好序,第一个数是a,就去找序号为a的数,然后以此类推即可
1 | // 表排序物理重排:根据table数组将list数组原地排序 |
最坏情况:有
时间复杂度:
3 A General Lower Bound for Sorting
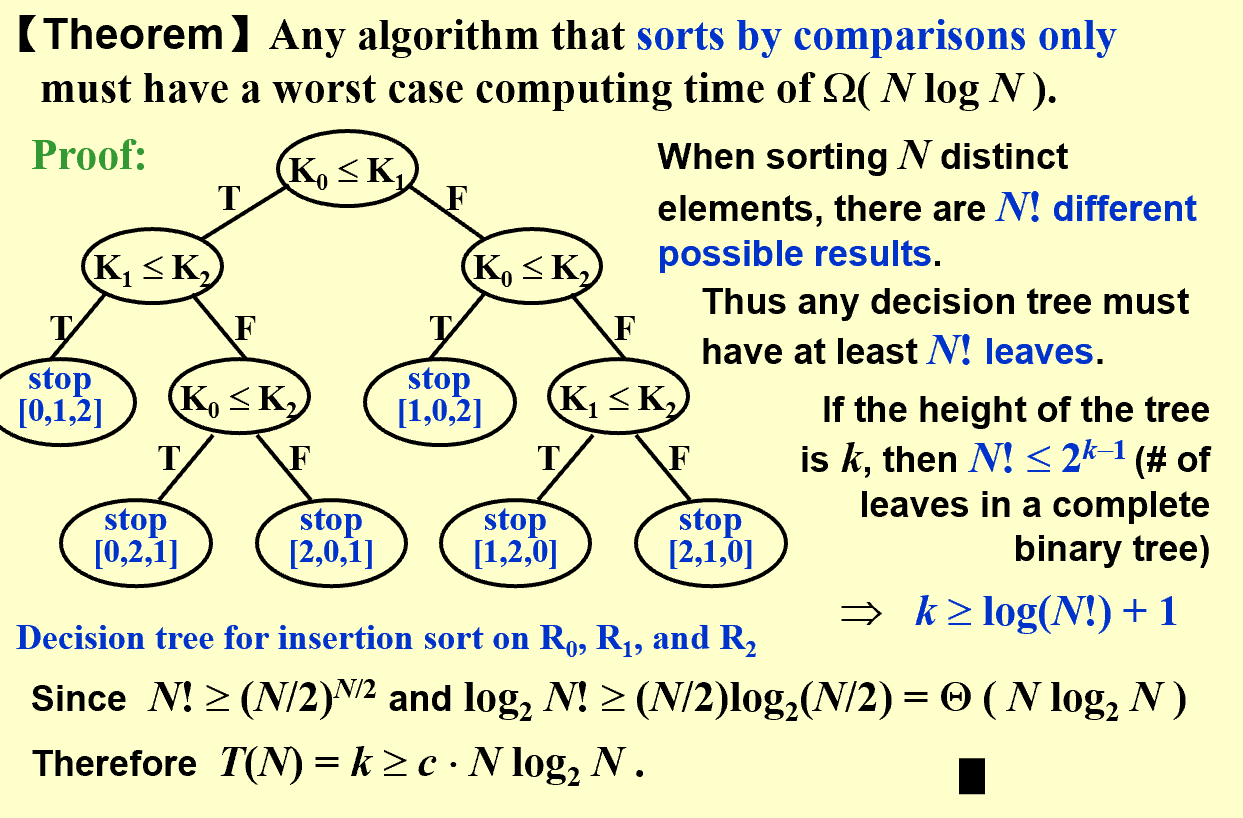
通用比较排序下界是针对所有仅通过比较元素大小来排序的算法,它们最快也不会超过
例如归并排序、堆排序、快速排序已经达到了这个下界
而之前提到的简单排序算法下界是针对仅通过交换相邻元素(更一般地,一次基本排序操作只能消除一个逆序对)来排序的算法
❌ 快速排序:可以交换任意两个不相邻的元素
❌ 归并排序:直接将元素复制到新数组,不需要相邻交换
❌ 堆排序:交换堆顶和堆底元素,也是不相邻交换
4 Bucket Sort and Radix Sort
既然纯比较的排序速度会被约束,那么我们能不能有不只使用比较的排序算法呢?
4.1 Bucket Sort
我们设想这么一个问题,现在有N名学生,他们的分数在0-100分之间,怎么给这n个学生按分数从低到高排序呢?
我们先创建101个“桶”(链表头),每个桶对应一个分数,遍历所有学生的分数,比如0号学生97分,就(头)插入到编号97的桶,1号学生88分,就(头)插入到88号桶,2号学生97分,就再头插到97号桶……
1 | void BucketSort(Student A[], int N) { |
遍历原数组需要
如果M和N同阶,那么时间复杂度就约为线性的,但如果M远大于N,空间开销就很大,时间复杂度也会变大
4.2 Radix Sort
下面直接引用Chapter2的内容
我们对64, 8, 216, 512, 27, 729, 0, 1, 343, 125进行排序
最后应排成0,1,8,27,64,125,216,343,512,729
如果让你来排,你会怎么做?
也许我们会先找三位数,三位数找到百位最大的729,然后是512,343……
或者从一位数找起,0最小,然后1,8,两位数中27小于64因为十位2小于7;如果要排的数中有26,28,那么我们知道28更大因为个位上的8更大
好了,这有什么用呢?记住上面排序时人的想法,其实跟基数排序很像
基数排序就是按位来排,根据基数N,从最低有效位开始,每个位进行桶排序
例如64, 8, 216, 512, 27, 729, 0, 1, 343, 125
十进制数,基数为10,那么我们按个位->十位->百位的顺序来排
第一轮 按个位排序
建10个桶(0-9),把数按个位放进对应的桶里
| 0 | 1 | 512 | 343 | 64 | 125 | 216 | 27 | 8 | 729 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
这里最好不要用数组,有可能要排序的数的某位数都一样,所以需要n*n的空间(n为基数,如十进制n=10,代表0-9)
可以每个桶是一个链表,元素放在桶里就等于元素插入对应链表,这样空间是O(N)
第二轮 按十位排序
如果有数十位相等,要按第一轮的顺序排(所以按第一轮排完后的数组去读就行,即0,1,512,343,…),因为这时要比较个位,所以第一轮大的数就应该大
| 0 1 8 |
512 216 |
125 27 729 |
343 | 64 | |||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
十位数相同的数,从上到下按第一轮的顺序
第三轮 按百位排序
百位数相同的数,从上到下按第二轮的顺序
| 0 1 8 27 64 |
125 | 216 | 343 | 512 | 729 | ||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
时间复杂度为
其中p为轮数,即位数,如十进制三位数p=3
n为元素个数
b为桶的数量,如十进制按位划分,b=10
二进制比如是32位整数,可以8位一划分,8位8位看,b=256
例如10000000 00000001
第一轮00000001放到1号桶
每轮在做的就是:
从0号桶开始遍历每个桶(b),遇到一个元素就放在对应桶里,共n次,故
基数排序适用于元素有多个key值,且键值有高低位之分,按字典序排序(前面字母顺序一样,就比后面的)
例如三位数
我们刚刚演示的就是按最低位(LSD)排序,先比较最低位,再逐个比较高位
也可以高位(MSD)优先,例如排序[729,63,503]
先找百位,7,5,0,729最大,其次503,然后63
MSD排序,首先先分类最高位
我们以扑克牌排序为例,扑克牌比较先比花色,花色一样时再比较面值,例如红桃J是小于黑桃3的
先排最高位,即建立4个桶(♣、♦、♥、♠),按花色把待排序的牌放进去
然后在每个桶里再利用任何方法对字面值排序
最后按花色桶顺序输出即可
当然这是比较简单的情形,如果有三个键值,例如三位数64, 8, 516, 512, 27, 729, 0, 1, 343, 125排序
先按百位排,
| 0 8 1 27 64 |
125 | 343 | 512 516 |
729 | |||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
接着在每个百位里,又按十位排,比如0号桶排完就是
| 0 8 1 |
27 | 64 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
在这个桶的每个十位里又按个位排,比如0号桶按十位排的0号桶,排完是
| 0 | 1 | 8 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
这是个递归的过程,最后合并,才得到按百位排的0号桶桶内正确顺序0,1,8,27,64
最坏时间复杂度是
- Title: Chapter 11 - Sorting (2)
- Author: Hare Fuyukawa
- Created at : 2026-05-24 20:30:44
- Updated at : 2026-06-03 17:38:49
- Link: https://redefine.ohevan.com/Data-Structure/DS/FDS-13/
- License: This work is licensed under CC BY-NC-SA 4.0.