Chapter 5 - Union-Find

定义
注意
补充、解释
其他
1 Intro
并查集(Union-Find)是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。它常用于判断两个元素是否属于同一个集合,并在需要时将两个集合合并。并查集在处理动态连通性问题时非常有效。
2 The Dynamic Equivalence Problem
Given S = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 } and 9 relations:
12 ~ 4, 3 ~ 1, 6 ~ 10, 8 ~ 9, 7 ~ 4, 6 ~ 8, 3 ~ 5, 2 ~ 11, 11~12.
The equivalence classes are { 2, 4, 7, 11, 12 }, { 1, 3, 5 }, { 6, 8, 9, 10 }
意思是,集合S中的12号元素和4号元素等价,等价是一种具有自反性、传递性、对称性的关系。
我们要做的就是根据给出的关系,分好等价类,即几个不相交的集合
这个问题中,最关键的就是合并和查找两个操作。
合并指把两个集合合并成一个集合。
查找指给定一个元素,找到它属于哪个集合。
当我们读进一个等价关系时,比如4和12等价,我们先查找4属于哪个集合(等价类),12属于哪个集合(等价类),如果一样,那就不用操作,如果不一样,就合并这两个集合,根据等价的性质,这样这个等价关系就被我们处理好了。
2.1 Basic Data Structure
怎么表示一个集合呢?我们用树来表示,比如集合{1,2,3,4},我们就可以用一棵根为3号元素,它的孩子是1,2,4号元素的树来表示。
其中1,2,4号元素指向3号元素,根指向自己,当然,后面我们就会知道,谁做根其实无所谓。
树的根就代表了一个集合,合并集合时,只需要让其中一个集合的根指向另一个集合的根即可。
如何实现这几棵树呢?我们可以使用数组。
下标从1开始,下标等于元素编号,数值是它的parent,不过下图中根是指向0,跟我们上面说的指向自己略有不同。
1 | void Initial(int* p, int n) |
于是对于这个问题,我们就可以这样解决:
1 | int main() |
2.2 Optimization
2.2.1 Path Compression
对于查找函数,查找的时间复杂度取决于该结点的深度,如查找4的根时,就要先到1再到6。如果我们能让每个结点直接指向根就好了,但是在合并两个集合时,会产生不直接指向根的结点是不可避免的。
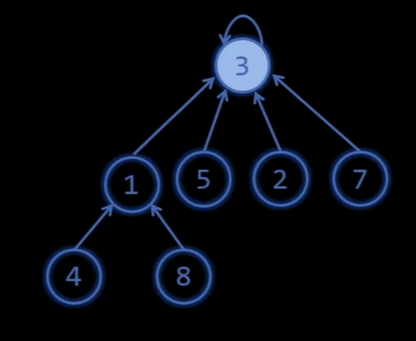
不过在一次查找中,我们可以将查找路径上的结点都做到直接指向根,下面的程序就是在查找根的过程中,经历的每一个结点都把它直接指向根,这样下次查找时的效率就会很高。
1 | int Find(int* p, int x) //查询编号为x的元素属于哪个集合 |
2.2.2 Union by Size/Height
Union by Size
在Union时,永远把节点数更少的那棵树,挂到节点数更多的那棵树的根节点上
Union by height
在Union时,永远把更矮的那棵树,挂到更高的那棵树的根节点上
根结点的值不再是自己,而是一个负数,这个数的绝对值就是这棵树的总结点数/高度
1 | void Initial(int* p, int n) |
按大小合并产生的树,树的高度小于等于
因此N次Union的时间复杂度就是
最后我们加上路径压缩,一次Union的复杂度变成常数
路径压缩会跟按高度压缩有冲突,因为路径压缩改变了树高,但记录却没有更新,不过我们不用管,按高度合并也叫按秩(rank)合并,秩就是指树的高度的一个上限,实际情况高度应该会更小
The union-by-size and union-by-height rules produce trees of almost exactly the same depth, so either rule can be used with path compression, and the resulting running time is essentially constant.
不管是 按大小合并 + 路径压缩,还是 按秩合并 + 路径压缩,它们的时间复杂度完全一样,都是:
这是阿克曼函数 (Ackermann Function) 的反函数。
它增长得极其极其慢:
当
α(N)≈3
当
α(N)≈5
所以一次Union就是常数时间复杂度
- Title: Chapter 5 - Union-Find
- Author: Hare Fuyukawa
- Created at : 2026-04-19 17:34:02
- Updated at : 2026-06-03 17:38:49
- Link: https://redefine.ohevan.com/Data-Structure/DS/FDS-6/
- License: This work is licensed under CC BY-NC-SA 4.0.