Chapter 2 - Lists,Stacks,Queues
0 Solution to Exercise 1 Abstract Data Type(ADT)
Definition
Data Type = {Obejcts}
即对于数据对象的说明、对操作的说明和数据如何表示、操作如何实现是分割开的,如下图specification representation & implementation
2 The List ADT 线性表的ADT描述:
初始化
根据位置找元素
找某个元素第一次出现的位置
插入
删除
返回线性表的长度
2.1 Array Implementation of Lists 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 typedef struct LNode * List ;struct LNode { ElementType data[MAX]; int last; }; List makeempty () { List Lptr; Lptr = (List)malloc (sizeof (struct LNode)); Lptr->last = -1 ; return Lptr; } struct LNode L ;List Lptr; L.data[i]; Lptr->last; int Find (List Lptr,ElementType x) { int i = 0 ; while (i<=Lptr->last && Lptr->data[i]!=x) { ++i; } if (i>Lptr->last) { return -1 ; } else { return i; } }
Insertion and Deletion
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void Insert (List Lptr,int i,ElementType x) { if (Lptr->last==MAX-1 ) { puts ("表满" ); return ; } if (i < 0 || i > Lptr->last ) { puts ("位置invalid" ); return ; } int j = 0 ; for (j=Lptr->last;j>=i+1 ;--j) { Lptr->data[j+1 ]=Lptr->data[j]; } Lptr->data[i+1 ]=x; Lptr->last++; } void Delete (List Lptr,int i) { if (i < 0 || i > Lptr->last ) { puts ("位置invalid" ); return ; } int j = 0 ; for (j=i;j<Lptr->last;++j) { Lptr->data[j]=Lptr->data[j+1 ]; } Lptr->last--; }
Insertion and deletion take O(N) time
2.2 Linked Lists
Dummy Head
A node that doesn’t include data and points to the actual head of the linked list.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 typedef struct LNode * List ;struct LNode { ElementType data; List next; }; int Length (List head) { int i = 0 ; List move = head; while (move->next != NULL ) { ++i; move=move->next; } return i; } List FindKth (List head,int k) { List move = head; int i = 0 ; while (i<k) { ++i; move=move->next; if (move==NULL ) { return NULL ; } } return move; } List FindX (List head,ElementType x) { List move = head->next; while (move!=NULL ) { if (move->data==x) return move; move=move->next; } return NULL ; }
Insertion and Deletion
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 List Insert (int i,List head,ElementType x) { List p = FindKth(head,i-1 ); if (p==NULL ) { puts ("Invalid i" ); return NULL ; } List s = (List)malloc (sizeof (struct LNode)); s->data = x; s->next = p->next; p->next = s; return head; } List Delete (int i,List head) { List p = FindKth(head,i-1 ); if (p==NULL ) { puts ("Invalid i" ); return NULL ; } List tmp = p->next; p->next = tmp->next; free (tmp); return head; }
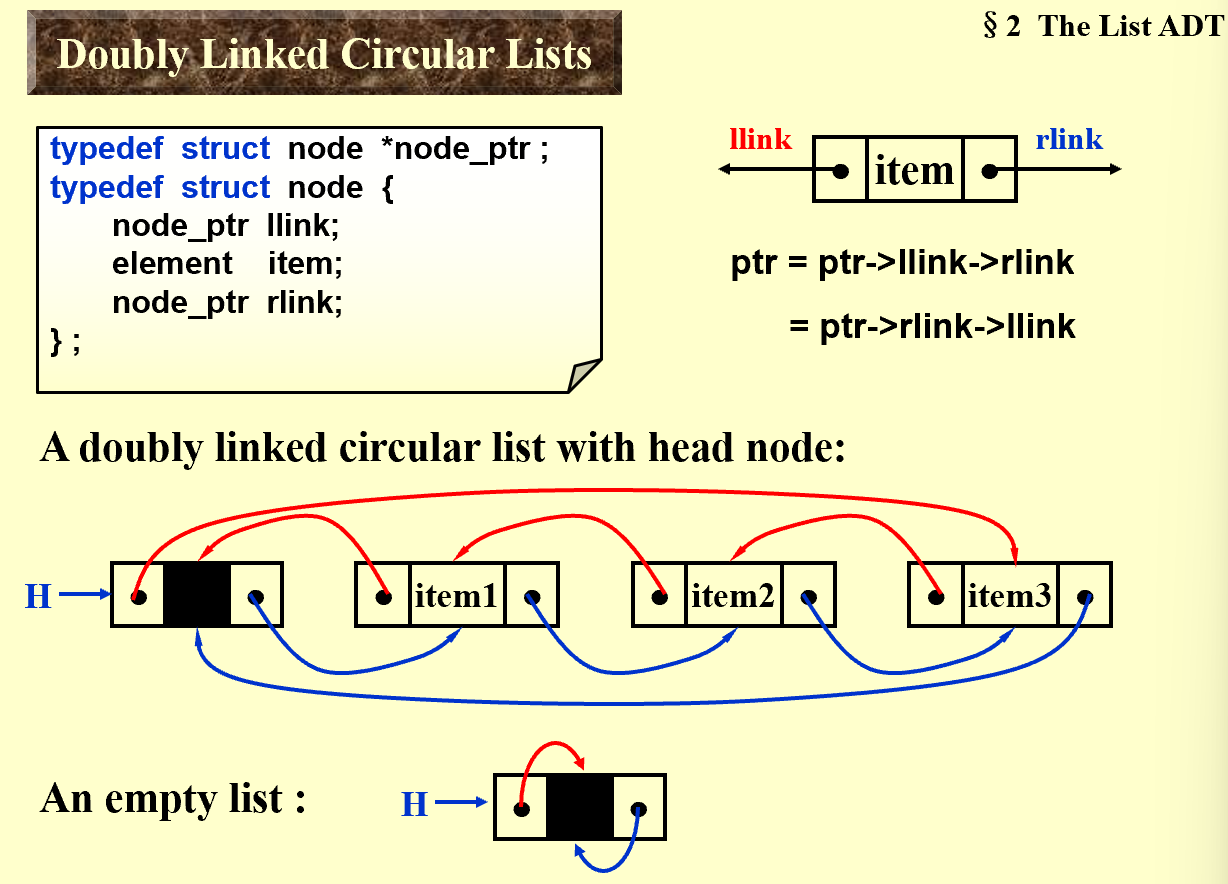
2.3 Doubly Linked Circular Lists
2.4 Applications 2.4.1 The Polynomial ADT Objects:
我们可以用数组实现,例如[1,2,0,1]表示
用链表实现
1 2 3 4 5 6 7 typedef struct poly_node * Poly_ptr ;struct poly_node { int coefficient; int exponent; Poly_ptr next; };
我们以次数递减排序
下面我们实现一下加法和乘法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 Poly_ptr createNode (int coef, int exp ) { Poly_ptr newNode = (Poly_ptr)malloc (sizeof (struct poly_node)); newNode->coefficient = coef; newNode->exponent = exp ; newNode->next = NULL ; return newNode; } Poly_ptr poly_add ( Poly_ptr a, Poly_ptr b ) { Poly_ptr dummy_head = createNode(0 ,0 ); Poly_ptr move = dummy_head; Poly_ptr pa = a->next; Poly_ptr pb = b->next; while (pa!=NULL && pb!=NULL ) { if (pa->exponent > pb->exponent) { move->next = createNode(pa->coefficient,pa->exponent); move = move->next; pa = pa->next; } else if (pa->exponent < pb->exponent) { move->next = createNode(pa->coefficient,pa->exponent); move = move->next; pb = pb->next; } else { int sum = pa->exponent + pb->exponent; if (sum != 0 ) { move->next = createNode(sum,pa->exponent); move = move->next; } pa = pa->next; pb = pb->next; } } while (pa != NULL ) { move->next = createNode(pa->coefficient,pa->exponent); move = move->next; pa = pa->next; } while (pb != NULL ) { move->next = createNode(pb->coefficient,pb->exponent); move = move->next; pb = pb->next; } return dummy_head; }
乘法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 typedef struct poly_node * Poly_ptr ;struct poly_node { int coefficient; int exponent; Poly_ptr next; }; Poly_ptr createNode (int coef, int exp ) { Poly_ptr newNode = (Poly_ptr)malloc (sizeof (struct poly_node)); newNode->coefficient = coef; newNode->exponent = exp ; newNode->next = NULL ; return newNode; } Poly_ptr poly_add ( Poly_ptr a, Poly_ptr b ) ; Poly_ptr single_multiply (int coef, int exp , Poly_ptr b) { Poly_ptr dummy_head = createNode(0 ,0 ); Poly_ptr move = dummy_head; Poly_ptr pb = b->next; while (pb != NULL ) { int new_coef = coef * b->coefficient; if (new_coef != 0 ) { int new_exp = exp + pb->exponent; move->next = createNode(new_coef,new_exp); move = move->next; } pb = pb->next; } return dummy_head; } void freePoly (Poly_ptr head) { Poly_ptr curr = head; while (curr) { Poly_ptr temp = curr; curr = curr->next; free (temp); } } Poly_ptr poly_multiply (Ploy_ptr a, Poly_ptr b) { Poly_ptr result = createNode(0 ,0 ); Poly_ptr pa = a->next; while (pa != NULL ) { Poly_ptr temp = single_multiply(pa->coefficient,pa->exponent,b); Poly_ptr newResult = poly_add(result,temp); freePoly(result); freePoly(temp); result = newResult; pa = pa->next; } return result; }
2.4.2 Radix Sort 我们先来讲桶排序(Bucket Sort)countcount[ai]++count数组,输出的结果就是排序结果
复杂度为
问题是m很大时怎么办呢
我们对64, 8, 216, 512, 27, 729, 0, 1, 343, 125进行排序
如果让你来排,你会怎么做?
好了,这有什么用呢?记住上面排序时人的想法,其实跟基数排序很像
基数排序就是按位来排,根据基数N,从最低有效位开始,每个位进行桶排序
例如64, 8, 216, 512, 27, 729, 0, 1, 343, 125第一轮 按个位排序
0
1
512
343
64
125
216
27
8
729
0
1
2
3
4
5
6
7
8
9
这里最好不要用数组,有可能要排序的数的某位数都一样,所以需要n*n的空间(n为基数,如十进制n=10,代表0-9)
第二轮 按十位排序 如果有数十位相等,要按第一轮的顺序排,因为这时要比较个位,所以第一轮大的数就应该大
0
512
125
343
64
0
1
2
3
4
5
6
7
8
9
十位数相同的数,从上到下按第一轮的顺序
第三轮 按百位排序
0
125
216
343
512
729
0
1
2
3
4
5
6
7
8
9
Then we are done !
时间复杂度为
每轮在做的就是:
虽然当b和n同阶,p为常数是复杂度是线性的,但运行时间的常数因子可能高
链表的内存不连续:缓存命中率低(CPU 访问连续内存比跳着访问快很多);
指针操作开销:每个元素要存指针,插入删除要操作指针,比数组的 “连续读写” 慢;
多轮遍历:即使 p=3,每一轮都要遍历所有元素和所有桶,而快排的log n因子其实不大(比如 n=1e6,log₂n≈20,3*(n+2048) vs 20n,实际中链表的开销可能让 3n 比 20n 还慢)。
2.4.3 Multilists 2.4.4 Sparse Matrix Representation 挖坑(
2.4.5 Cursor 3 The Stack ADT
Stack
栈(stack) 是限制插入和删除只能在一个位置上进行的线性表,该位置是表的末端,叫做栈的顶(top) 入栈(push) 删除数据叫出栈(pop)
3.1 Linked List Implementation (with a dummy head) 栈的链式存储实际上是单向链表,栈顶指针top在链表的头处
如果表尾作top,top指针指向表尾,则删除时找不到前面一个结点,故单向链表只有表头(dummy head)能做top
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 typedef struct SNode { ElementType data; struct SNode * next ; }SNode; SNode* Create_stack () { SNode* head = (SNode*)malloc (sizeof (SNode)); head->next = NULL ; return head; } int Is_empty (SNode* head) { return (head->next==NULL ) } void Push(SNode* head,ElementType x){ SNode* new = malloc (sizeof (SNode)); if (new==NULL ) { puts ("error" ); return ; } new->data = x; new->next = head->next; head->next = new; } ElementType Pop (SNode* head) { if (Is_empty(head)) { puts ("Empty Stack" ); return ERROR; } SNode tmp = head->next; head->next = tmp->next; ElementType pop_element = tmp->data; free (tmp); return pop_element; }
频繁使用malloc和free是expensive的(为什么? Ask AI)
3.2 Array Implementation 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 typedef struct { ElementType* stack_array; unsigned int stack_size; int top; }STACK; STACK* create_stack (unsigned int max) { STACK* s; s = (STACK*)(malloc (sizeof (STACK))); s->stack_array = (ElementType*)malloc (sizeof (ElementType)*max); if (s->stack_array == NULL ) { free (s); puts ("error" ); return ; } s->top = -1 ; s->stack_size = max; return s; } void dispose_stack (STACK* s) { if (s) { free (s->stack_array); free (s); } } void Push (STACK* p,ElementType x) { if (p->top == p->stack_array-1 ) { puts ("栈满" ); return ; } p->stack_array[++(p->top)] = x; } ElementType Pop (STACK* p) { if (p->top == -1 ) { puts ("栈空" ); return ERROR; } return p->stack_array[p->(top--)]; }
The stack model must be well encapsulated. That is, no part of your code, except for the stack routines, can attempt to access the Array or TopOfStack variable.