Chapter 9 - Network Flow & MST
1 Network Flow Problem
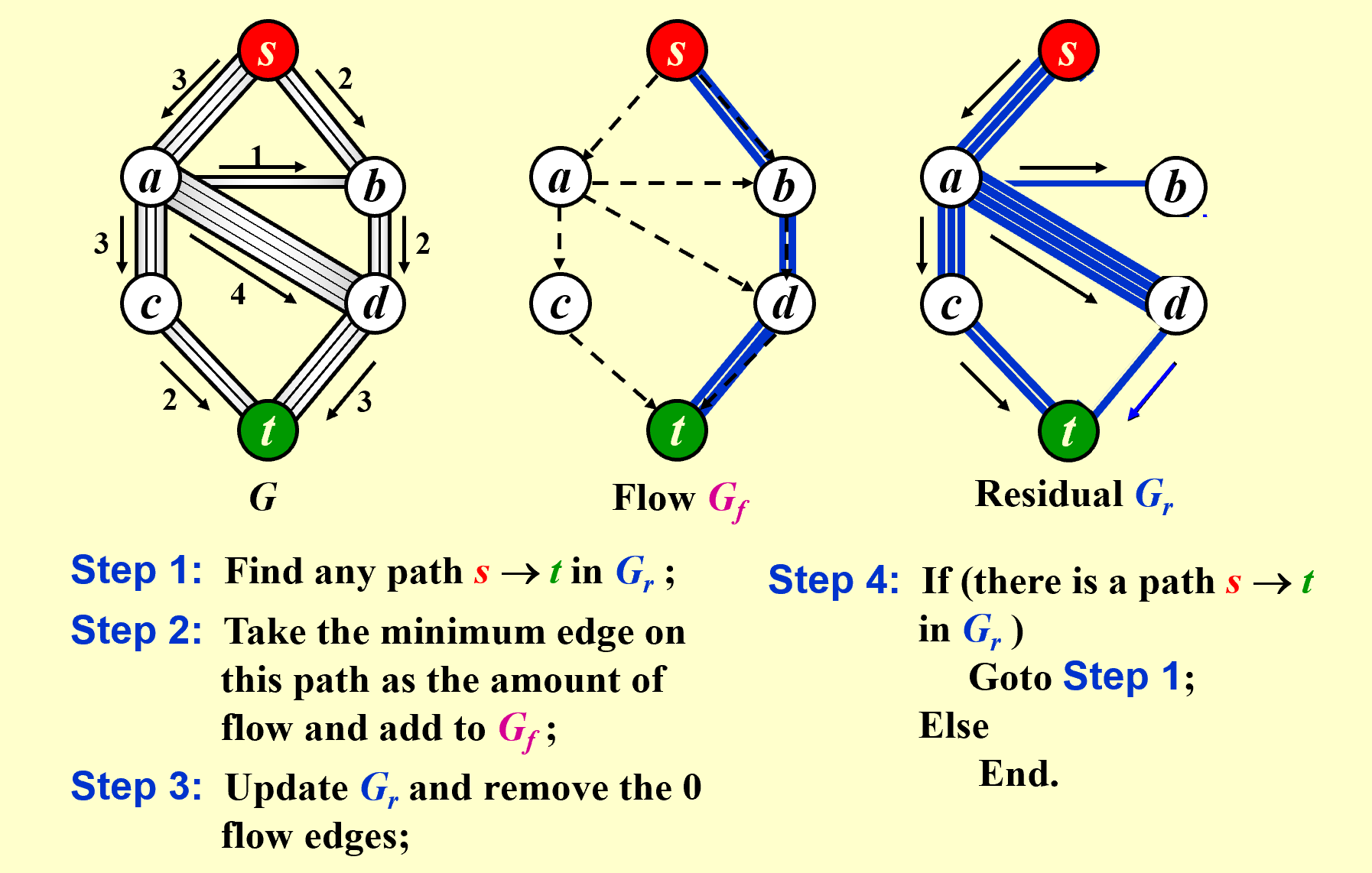
一个简单的算法如图所示,每次找到一条从s到t的路径(不能有环)(增广路径 augmenting path
用最左边的图减去最右边的图就得到Flow的图,即中间的图,就是结果
然而,这种算法有时会失败,如果我们先找了s->a->d->t这条路,算法直接终止,而这并不是最大流,而是阻塞流,这个算法的问题就在于无法“反悔”,如果优先找到了不是最大流的阻塞流,算法就会失效
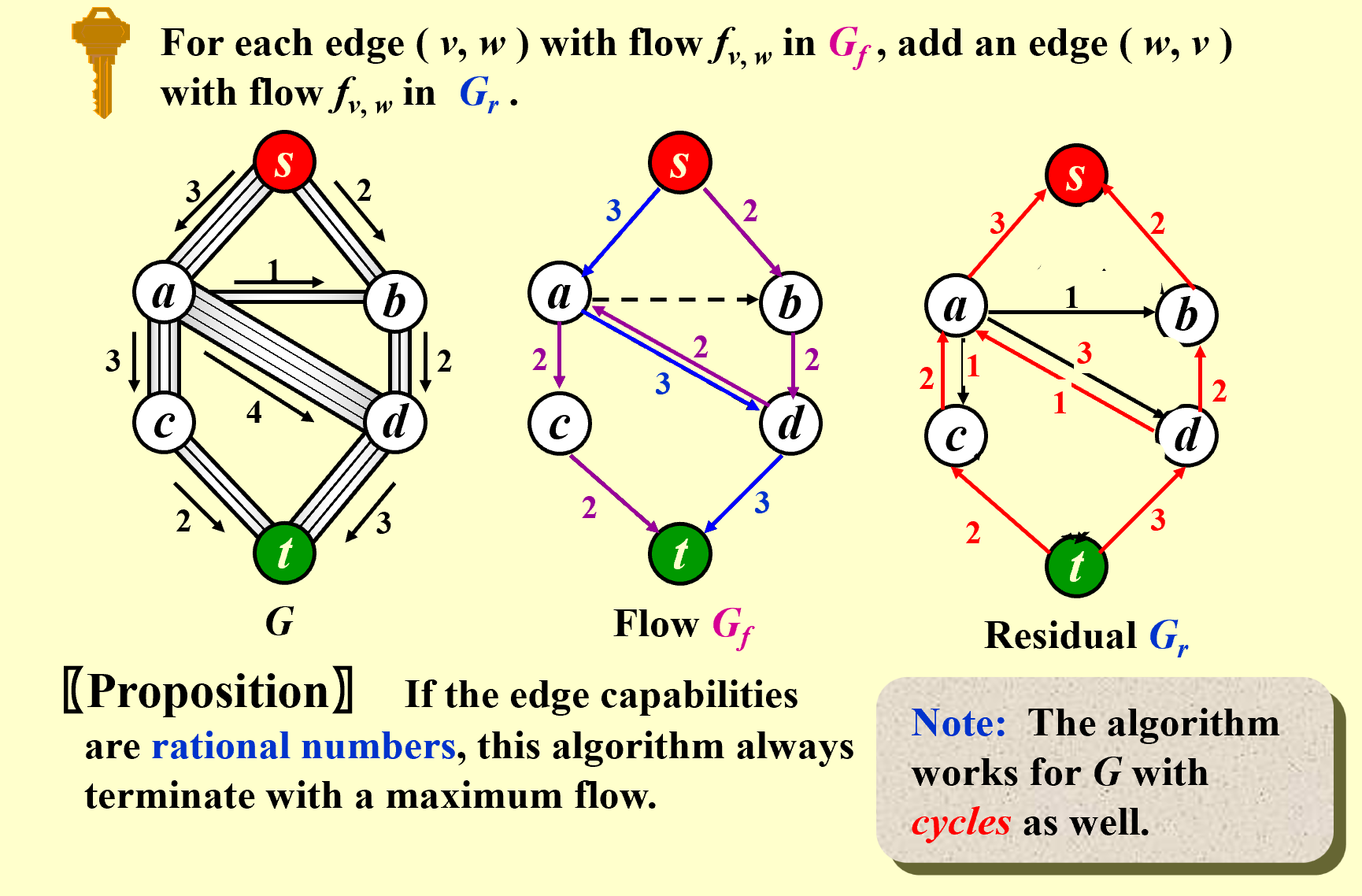
1.1 Ford-Fulkerson Algorithm s->a->d->t,我们首先在residual graph里减去这条路的最小容量3,然后添加反向路径t->d,d->a,a->s,反向路径大小为3
算法结束后,忽略residual graph里的反向路径,就得到了residual graph,原图减去剩余就是流的图。
当然也可以使用Flow的图,走一条路就画在Flow的图上,但最后要减去反向的路径(如a到d是3-2=1),从上面的Flow图也可看出到底“反悔(Undo)”是怎么实现的,我们从d到a那条其实就是反悔之前直接从a到d流了3份的操作,改为流一份。
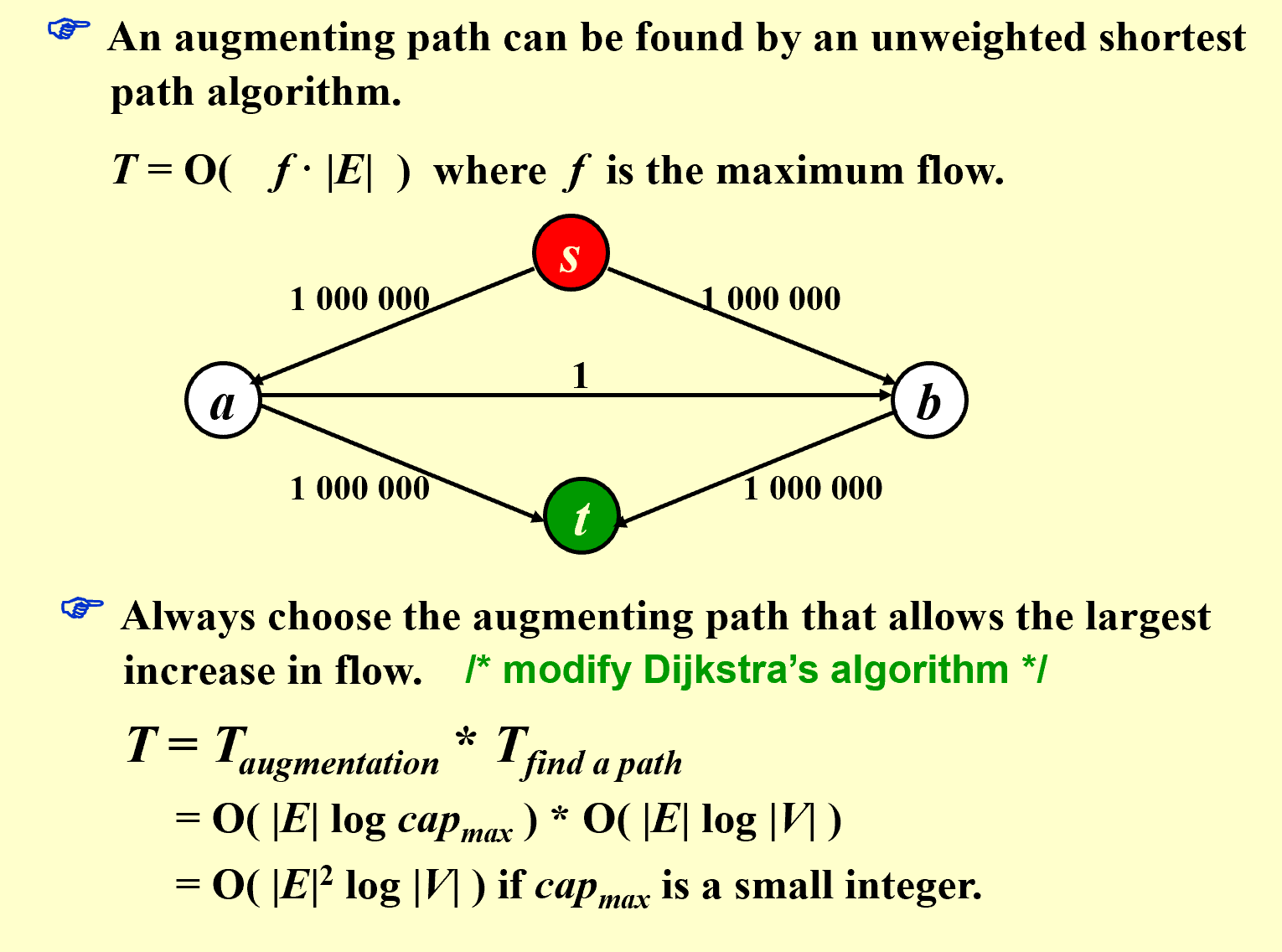
1.2 Edmonds-Karp Algorithm 找路径时把图看作无权图,使用BFS找最短路径,其他和上面的算法一样,找路径复杂度为
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #include <stdio.h> #include <string.h> #include <stdbool.h> #define MAX_V 100 #define INF 1e9 int capacity[MAX_V][MAX_V]; int parent[MAX_V]; int n; bool bfs (int s, int t) { bool visited[MAX_V]; memset (visited, 0 , sizeof (visited)); int queue [MAX_V]; int head = 0 , tail = 0 ; queue [tail++] = s; visited[s] = true ; parent[s] = -1 ; while (head < tail) { int u = queue [head++]; for (int v = 0 ; v < n; v++) { if (!visited[v] && capacity[u][v] > 0 ) { if (v == t) { parent[v] = u; return true ; } queue [tail++] = v; parent[v] = u; visited[v] = true ; } } } return false ; } int edmondsKarp (int s, int t) { int max_flow = 0 ; while (bfs(s, t)) { int path_flow = INF; for (int v = t; v != s; v = parent[v]) { int u = parent[v]; if (capacity[u][v] < path_flow) { path_flow = capacity[u][v]; } } for (int v = t; v != s; v = parent[v]) { int u = parent[v]; capacity[u][v] -= path_flow; capacity[v][u] += path_flow; } max_flow += path_flow; } return max_flow; } int main () { n = 6 ; memset (capacity, 0 , sizeof (capacity)); capacity[0 ][1 ] = 16 ; capacity[0 ][2 ] = 13 ; capacity[1 ][2 ] = 10 ; capacity[1 ][3 ] = 12 ; capacity[2 ][1 ] = 4 ; capacity[2 ][4 ] = 14 ; capacity[3 ][2 ] = 9 ; capacity[3 ][5 ] = 20 ; capacity[4 ][3 ] = 7 ; capacity[4 ][5 ] = 4 ; printf ("该网络的最大流量为: %d\n" , edmondsKarp(0 , 5 )); return 0 ; }
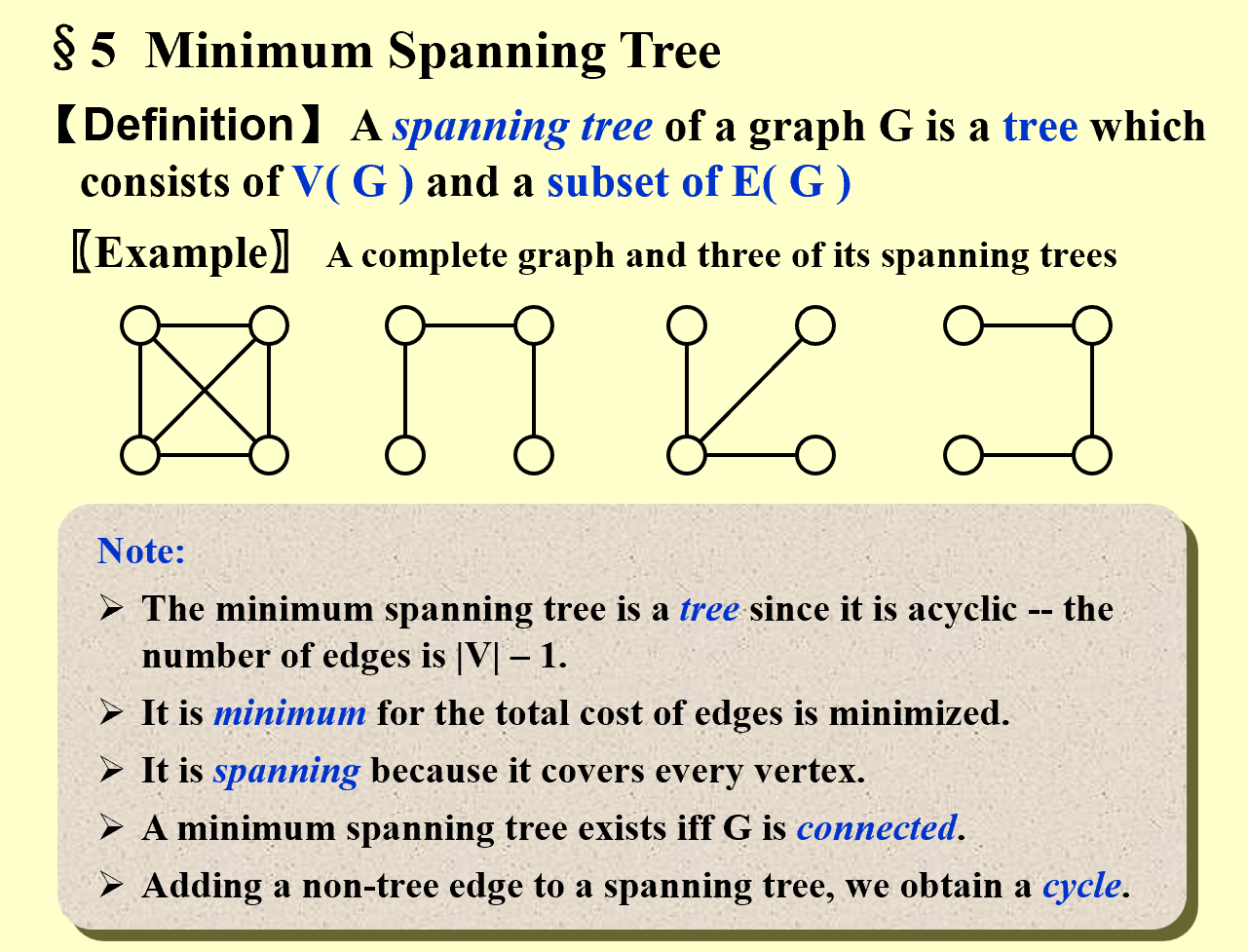
2 Minimum Spanning Tree
2.1 Prim’s Algorithm 跟Dijsktra算法很像,先选一个源点,加入集合(这个集合存储着在生成树里的点),然后更新邻接的边权,接着再选出到集合里的点边权最小的点,重复操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <stdio.h> #include <stdlib.h> #include <limits.h> #define Infinity INT_MAX #define NotAVertex -1 #define MaxVertexNum 100 typedef struct { int Dist; int Known; int Path; } TableEntry; typedef TableEntry Table[MaxVertexNum];typedef int Vertex;typedef int Weight;typedef struct AdjNode { Vertex adjvex; Weight weight; struct AdjNode *next ; } AdjNode; typedef struct { AdjNode *head[MaxVertexNum]; int vertexNum; int edgeNum; } Graph; void InitTable (Vertex start, Graph *G, Table T) { for (int i = 0 ; i < G->vertexNum; i++) { T[i].Dist = Infinity; T[i].Known = 0 ; T[i].Path = NotAVertex; } T[start].Dist = 0 ; } Vertex FindMinDist (Table T, Graph *G) { int minDist = Infinity; Vertex minV = NotAVertex; for (int i = 0 ; i < G->vertexNum; i++) { if (!T[i].Known && T[i].Dist < minDist) { minDist = T[i].Dist; minV = i; } } return minV; } int Prim_Basic (Graph *G, Vertex start, Table T) { InitTable(start, G, T); Vertex V, W; AdjNode *p; int totalWeight = 0 ; for (int i = 0 ; i < G->vertexNum; i++) { V = FindMinDist(T, G); if (V == NotAVertex) { printf ("图不连通,无最小生成树\n" ); return -1 ; } T[V].Known = 1 ; totalWeight += T[V].Dist; p = G->head[V]; while (p != NULL ) { W = p->adjvex; if (!T[W].Known) { if (p->weight < T[W].Dist) { T[W].Dist = p->weight; T[W].Path = V; } } p = p->next; } } return totalWeight; }
外层循环执行 | V | 次(每个顶点处理 1 次)
2.2 Kruskal’s Algorithm Kruskal 是基于边的贪心 —— 把所有边按权值从小到大排序,依次加入生成树,只要不形成环就保留
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void Kruskal ( Graph G ) { T = { } ; while ( T contains less than |V| - 1 edges && E is not empty ) { choose a least cost edge (v, w) from E ; delete (v, w) from E ; if ( (v, w) does not create a cycle in T ) add (v, w) to T ; else discard (v, w) ; } if ( T contains fewer than |V| - 1 edges ) Error ( “No spanning tree” ) ; }
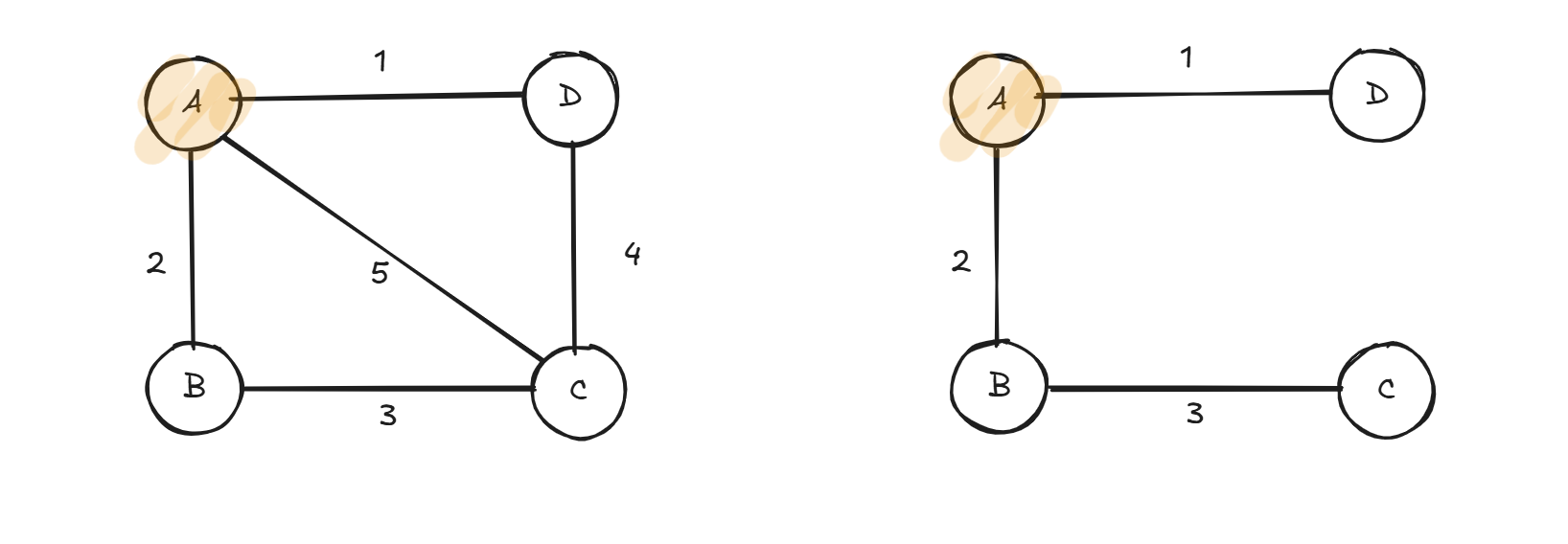
我们以上面的图片为例,首先选AD边,然后选AB边,然后选BC边,这时已经有三条边了,结束
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 #include <stdio.h> #include <stdlib.h> #include <limits.h> #define MaxVertexNum 100 #define MaxEdgeNum 10000 typedef int Vertex;typedef int Weight;typedef struct { Vertex u; Vertex v; Weight weight; } Edge; typedef struct { Edge edges[MaxEdgeNum]; int vertexNum; int edgeNum; } Graph; int parent[MaxVertexNum];int rank[MaxVertexNum];void InitUnionFind (int n) { for (int i = 0 ; i < n; i++) { parent[i] = i; rank[i] = 0 ; } } int Find (int v) { if (parent[v] != v) { parent[v] = Find(parent[v]); } return parent[v]; } void Union (int v, int w) { int rootV = Find(v); int rootW = Find(w); if (rootV == rootW) return ; if (rank[rootV] < rank[rootW]) { parent[rootV] = rootW; } else { parent[rootW] = rootV; if (rank[rootV] == rank[rootW]) { rank[rootV]++; } } } int CompareEdge (const void *a, const void *b) { Edge *edgeA = (Edge *)a; Edge *edgeB = (Edge *)b; return edgeA->weight - edgeB->weight; } int Kruskal (Graph *G, Edge *mstEdges) { int totalWeight = 0 ; int mstEdgeCount = 0 ; InitUnionFind(G->vertexNum); qsort(G->edges, G->edgeNum, sizeof (Edge), CompareEdge); for (int i = 0 ; i < G->edgeNum && mstEdgeCount < G->vertexNum - 1 ; i++) { Edge e = G->edges[i]; int rootU = Find(e.u); int rootV = Find(e.v); if (rootU != rootV) { mstEdges[mstEdgeCount++] = e; totalWeight += e.weight; Union(rootU, rootV); } } if (mstEdgeCount < G->vertexNum - 1 ) { printf ("图不连通,无最小生成树\n" ); return -1 ; } return totalWeight; } void PrintMST (Edge *mstEdges, int vertexNum, int totalWeight) { printf ("最小生成树总权值:%d\n" , totalWeight); printf ("生成树边:\n" ); for (int i = 0 ; i < vertexNum - 1 ; i++) { printf ("v%d -- v%d (权值:%d)\n" , mstEdges[i].u + 1 , mstEdges[i].v + 1 , mstEdges[i].weight); } }