Chapter 11 - Sorting (1)

定义
注意
补充、解释
其他
1 Preliminaries
1 | void X_Sort(ElementType A[], int N) |
2 Insertion Sort
想象你抽扑克牌
你先抽到8,当然,拿在手里
接着抽到K,没问题,在8右边
抽到9,放到8和K之间
抽到10,比K小,比9大,放在9和K之间…
1 | void InsertionSort(ElementType A[], int N) |
我们以[34, 8, 64, 51, 32, 21]为例
34>8,那么变成[34, 34, 64, 51, 32, 21]
这时j=0了,停止循环,在这个位置“插入”8,变成[8, 34, 64, 51, 32, 21]
继续,64比前面都大,没问题
54比64小,先“记住”54(Tmp),然后往前一直比,如果前面有比它大的,就挪到它的位置,最后停在哪里就在哪里插入,比如停在34,51比34大,所以变成[8, 34, 64(隐藏的51), 64(64已经“后移”了), 32, 21]再到[8, 34, 51(51来到64让出的位置), 64, 32, 21]
32就更明显,过程为[8, 34, 51, 64(隐藏的32,下面跟51比), 64(其实64“后移”了), 21][8, 34, 51(隐藏的32), 51, 64, 21][8, 34(隐藏的32), 34, 51, 64, 21]
最后比完了,8<32[8, 32, 34, 51, 64, 21]
这就像数字为32的牌,最开始在64的右边,跟64比,比它小,放在它左边,跟51比,又小,放在左边……只不过正和人一样,在前面已经排好的情况下,我们可以一直扫描到比32小的数,这就是程序正在干的,而不是每扫描到一个数就交换一次
最坏情况,逆序的数组,如[3,2,1],1要比两次,2比一次…
n个数降序排列,时间复杂度就是
最好情况就是已经排好了,那么每个数检验一次,即内层循环不会被执行,只做判定,外层循环n-1次都是常数时间,时间复杂度为
3 A Lower Bound for Simple Sorting Algorithms
数组中的逆序对:i < j但 A[i] > A[j]
数组[34, 8, 64, 51, 32, 21]有9个逆序对
(34,8) (34,32) (34,21)
(64,51) (64,32) (64,21)
(51,32) (51,21)
(32,21)
交换两个相邻的逆序元素,就移除一个逆序对
插入排序的本质就在于每一次元素后移,都在消除一个逆序对
这里的后移就是指A[j] = A[j - 1];这一步
假设数组有N个元素,I个逆序对,内层循环中赋值操作执行的次数就是I次
在每个外层循环中,取出TMP一次操作,A[j] = Tmp一次操作,共常数次操作,外层一共循环N-1次
所以时间复杂度就是
The average number of inversions in an array of
Any algorithm that sorts by exchanging adjacent elements requires
作业2-4 2-5
4 Shell Sort
希尔排序是基于插入排序的一种改进,利用了插入排序在数据个数较少时效率高、数据较有序时效率高的优点
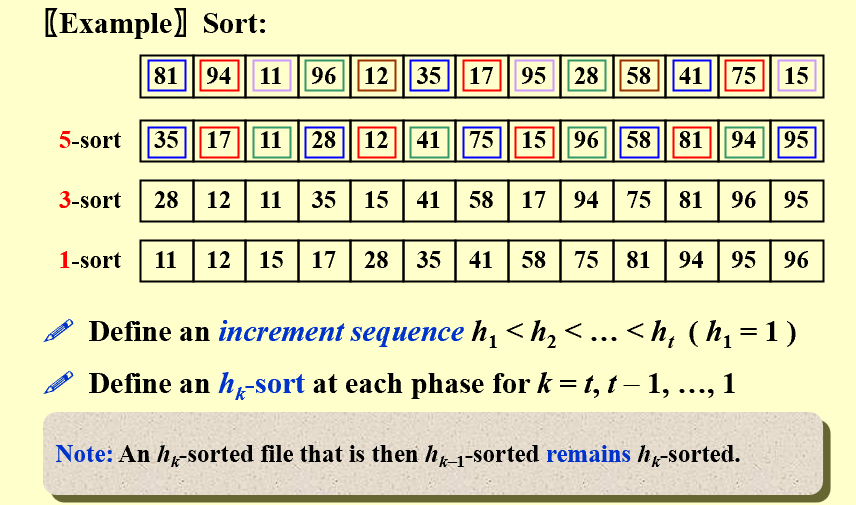
对于要排列的数,我们定义增量序列,例如图中增量序列是1,3,5
5-sort意思就是每5个分成一组,在组内插入排序,例如81,35,41是一组,94,17,75是一组等等
排完之后,按增量序列顺序进行3-sort直到进行1-sort
1 | void Shellsort( ElementType A[ ], int N ) |
上面的伪代码,例如increment=5,就从35,17,95这样一直排下去,轮到一个数其实是在它的组内插入排序
使用希尔增量(每次除以2,最开始是N/2)最坏时间复杂度
反例说明:数组 [1,9,2,10,3,11,4,12,5,13,6,14,7,15,8,16]
8-sort、4-sort、2-sort 都不会改变数组(因为偶数位置都是大数,奇数位置都是小数)
只有最后 1-sort 才真正排序,时间复杂度退化为 O (N²)
根本原因:Shell 增量中相邻增量不互质,小增量无法有效移动大增量留下的逆序对,如8、4、2排序的结果都是一样的。
适用场景:适合排序中等规模输入(数万级别),实现简单,实际性能优于简单插入排序和选择排序
定义:hₖ = 2ᵏ - 1(例如:1,3,7,15,31…)
优势:相邻增量互质,避免了 Shell 增量的缺陷
复杂度:最坏情况
定义:序列为 {1, 5, 19, 41, 109, …},项的形式为 9×4ⁱ - 9×2ⁱ + 1 或 4ⁱ - 3×2ⁱ + 1
复杂度:平均情况
要注意的是,希尔排序不具有稳定性,所谓排序的稳定性,指的是在排序算法中,如果两个元素的值相等,它们在排序后的相对前后顺序与排序前保持一致。
5 Heap Sort
我们可以利用最大堆或最小堆来排序
简单的想法是
1 | { |
但这样需要额外的O(N)空间
1 | void Heapsort( ElementType A[ ], int N ) |
由于我们之前给出的输入是数组,所以不得不从0开始排,相应地,i号结点的左儿子就是2i+1,右儿子是2i+2
时间复杂度:最坏、平均、最好情况均为 O(N log N)
平均比较次数:2N log N - O(N log log N)
特点:
是不稳定排序
虽然理论复杂度优于希尔排序,但实际运行速度比使用 Sedgewick 增量的希尔排序慢(因为堆排序每次的常数大)
适合对内存要求严格的场景,不需要额外空间;规模足够大、够随机
6 Merge Sort
合并 [1,13,24,26] 和 [2,15,27,38]
过程:用三个指针分别指向左数组、右数组和临时数组的当前位置,比较两个指针指向的元素,将较小的放入临时数组,指针后移;当其中一个数组遍历完后,将另一个数组的剩余元素全部复制到临时数组。
时间复杂度:
1 | // 递归排序函数 |
分析时间复杂度
1 | T(N) = 2T(N/2) + O(N) |
空间复杂度是
若在Merge函数中每次都声明局部临时数组:递归深度为log N,每层需要 O (N) 空间,总空间复杂度 O(N log N)
归并排序是稳定的排序,由于需要线性的额外空间,内部排序几乎不使用,但外部排序很好用,什么是外部排序,也许是下学期的事情了。
6.1 拓展:为什么这三种算法比插入排序快?
插入排序一次只能消除一个逆序对,而这些算法一次都能消除多个逆序对
ai_answer
三种排序算法如何一次消除多个逆序对
这正是它们比插入排序(每次只能消除1个逆序对)快的核心原因。我会结合PPT中的例子和原理,逐一拆解每种算法的”批量消逆序对”机制。
## 前置铺垫:插入排序的根本局限
逆序对定义:对于数组中任意两个位置 i<j,若 A[i] > A[j],则 (i,j) 是一个逆序对。
- 插入排序每次只能交换相邻元素,因此一次交换最多消除1个逆序对
- 最坏情况下(逆序数组)有
N(N-1)/2个逆序对,时间复杂度必然是Θ(N²)
希尔、堆、归并排序的共同突破:通过非相邻元素的移动/合并,一次操作消除多个逆序对
## 一、希尔排序:跳跃式移动,批量消除跨距逆序对
### 核心机制:增量分组 + 长距离移动
希尔排序通过增量h将数组分成h个独立子序列,每个子序列中元素间隔h个位置。此时插入排序的元素移动步长是h,而不是1,因此一次移动可以跳过h-1个元素,同时消除h个逆序对。
### PPT示例的具体过程
原始数组:[81, 94, 11, 96, 12, 35, 17, 95, 28, 58, 41, 75, 15]
#### 1. 5-sort阶段(h=5)
以子序列2(索引2,7,12)为例:11, 95, 15
- 插入排序时,15需要从索引12移动到索引7
- 移动步长是5,一次移动跳过了索引8-11的4个元素
- 同时消除了逆序对
(7,12)(95>15)和(2,12)(11<15,不消除)→ 实际消除1个,但如果是更大的数组,一次移动可以消除更多
再看子序列0(索引0,5,10):81, 35, 41
- 35从索引5移动到索引0,步长5
- 消除逆序对
(0,5)(81>35) - 41从索引10移动到索引5,步长5
- 消除逆序对
(0,10)(81>41)和(5,10)(35<41,不消除)
#### 2. 增量递减的叠加效果
- 大增量阶段:消除大范围、长距离的逆序对(比如把数组末尾的小元素快速移到前面)
- 小增量阶段:消除中范围的逆序对,进一步细化数组有序性
- 1-sort阶段:数组已基本有序,剩余逆序对极少,插入排序只需少量操作
### 为什么增量序列很重要?(PPT反例解释)
PPT中Shell增量的最坏情况:[1,9,2,10,3,11,4,12,5,13,6,14,7,15,8,16]
- 8-sort、4-sort、2-sort时,增量都是偶数,相邻增量不互质
- 奇数位置全是小数,偶数位置全是大数,小增量无法跨奇偶位置移动元素
- 所有逆序对都只能留到1-sort阶段消除,退化为O(N²)
- Hibbard增量(2ᵏ-1)相邻增量互质,解决了这个问题,确保每个增量都能有效消除新的逆序对
## 二、堆排序:最大值直接归位,一次性消除所有相关逆序对
### 核心机制:堆顶最大值的全局归位
堆排序利用大顶堆的性质:堆顶元素是整个数组的最大值。每次将堆顶最大值与数组末尾元素交换,一次交换就能将最大值放到最终正确的位置,同时消除最大值与后面所有元素形成的逆序对。
### 具体过程(结合PPT算法2)
建堆阶段(O(N)):
- 从最后一个非叶子节点开始向下调整(PercDown)
- 当一个大元素在堆的下层时,一次向下调整可以连续交换多个层级,一次移动消除多个逆序对
- 例如:一个元素在第k层,需要移动到第1层,一次调整就能跳过k-1个节点,消除k-1个逆序对
排序阶段(O(N log N)):
- 第1次交换:堆顶最大值与索引N-1交换 → 最大值归位,消除它与后面N-1个元素的所有逆序对(最多N-1个)
- 第2次交换:新堆顶(次大值)与索引N-2交换 → 次大值归位,消除它与后面N-2个元素的所有逆序对
- …
- 第i次交换:消除最多(N-i)个逆序对
## 三、归并排序:合并有序子数组,批量消除跨子数组逆序对
### 核心机制:有序子数组的批量合并
归并排序的”分治”思想中,合并(Merge)步骤是批量消除逆序对的关键。当合并两个已经有序的子数组L和R时:
- 如果L中的当前元素
L[i] > R[j],那么L中从i到末尾的所有元素都大于R[j] - 此时将R[j]放入临时数组,一次操作就能消除 (len(L)-i) 个逆序对
### PPT合并示例的扩展
PPT示例:合并 L=[1,13,24,26] 和 R=[2,15,27,38]
- 比较1和2 → 放1,消除0个逆序对
- 比较13和2 → 放2,此时L中13,24,26都大于2 → 一次消除3个逆序对
- 比较13和15 → 放13,消除0个
- 比较24和15 → 放15,此时L中24,26都大于15 → 一次消除2个逆序对
- 比较24和27 → 放24,消除0个
- 比较26和27 → 放26,消除0个
- 放剩余的27,38 → 消除0个
- 本次合并共消除
3+2=5个逆序对,仅用了7次比较
### 极端情况的威力
如果左子数组全大于右子数组:L=[5,6,7,8],R=[1,2,3,4]
- 合并时,右子数组的4个元素会依次被放入临时数组
- 每个右元素都能消除4个逆序对
- 总共消除
4×4=16个逆序对,仅用了8次比较 - 这是归并排序效率最高的情况
### 分治的叠加效果
- 分解阶段:将大数组分成2个、4个、8个…直到单个元素
- 每个子数组内部的逆序对在递归排序时被消除
- 合并阶段:消除跨两个子数组的逆序对
- 所有逆序对都会被恰好消除一次,因此时间复杂度稳定为O(N log N)
## 三种算法的”批量消逆序对”对比
| 算法 | 一次操作最多消除逆序对数量 | 核心操作 | 逆序对消除特点 |
|---|---|---|---|
| 希尔排序 | h(当前增量) | 长距离插入排序 | 分阶段消除,大增量消大范围,小增量消小范围 |
| 堆排序 | N-i(第i次交换) | 堆顶最大值归位 | 从大到小逐个消除全局最大值的所有逆序对 |
| 归并排序 | len(L)-i(合并时) | 有序子数组合并 | 批量消除跨子数组的逆序对,效率最稳定 |
## 关键结论
- 所有O(N log N)级别的排序算法,本质都是突破了”一次只能消除1个逆序对”的限制
- 希尔排序通过跳跃式移动实现批量消除,实现最简单,适合中等规模数据
- 堆排序通过全局最大值归位实现批量消除,原地排序,适合内存受限场景
- 归并排序通过有序合并实现批量消除,效率最稳定且是稳定排序,适合外部排序
- Title: Chapter 11 - Sorting (1)
- Author: Hare Fuyukawa
- Created at : 2026-05-16 23:06:55
- Updated at : 2026-06-03 17:38:49
- Link: https://redefine.ohevan.com/Data-Structure/DS/FDS-12/
- License: This work is licensed under CC BY-NC-SA 4.0.